
Введение
Небезопасный публичный сервис - одна из наиболее часто встречающихся неправильных конфигураций в облачных средах. Такие сервисы можно обнаружить в Интернете, и они могут представлять значительный риск для облачных систем в той же инфраструктуре. Известные группы вымогателей - такие как REvil и Mespinoza - используют открытые сервисы для получения первоначального доступа к средам жертв. Используя инфраструктуру ловушек-ханипотов из 320 узлов, развернутых по всему миру, исследователи стремятся лучше понять атаки на открытые сервисы в публичных облаках.
Исследователи Unit 42 развернули в инфраструктуре ханипотов несколько экземпляров протокола удаленного рабочего стола (RDP), протокола SSH, блока серверных сообщений (SMB) и базы данных Postgres. Исследователи обнаружили, что 80% из 320 точек были скомпрометированы в течение 24 часов, а все расставленные ловушки оказались взломаны в течение недели.
Краткие результаты исследования:
- SSH был наиболее атакуемым протоколом. Количество атакующих и компрометирующих событий было гораздо выше, чем для трех других сервисов.
- Наиболее атакованный SSH-ханипот был взломан 169 раз за один день.
- В среднем, каждый SSH-ханипот был взломан 26 раз в день.
- Один атакующий скомпрометировал 96% из 80 наших ханипотов Postgres по всему миру в течение 30 секунд.
- 85% IP-адресов атакующих были замечены только в один день. Это число указывает на неэффективность межсетевых экранов на основе IP-адресов третьего уровня, поскольку злоумышленники редко используют одни и те же IP-адреса для проведения атак. Список вредоносных IP-адресов, созданный сегодня, скорее всего, устареет уже завтра.
Скорость управления уязвимостями обычно измеряется в днях или месяцах. Тот факт, что злоумышленники могут найти и скомпрометировать наши сервисы за считанные минуты, просто шокирует. Это исследование демонстрирует опасность незащищенных сервисов, а результат подтверждает важность быстрого устранения проблем безопасности и их исправления. Когда неправильно настроенный или уязвимый сервис выходит в Интернет, злоумышленникам требуется всего несколько минут, чтобы обнаружить и скомпрометировать его. Нет права на ошибку, когда речь идет о сроках исправления проблем безопасности.
Prisma Cloud может выявлять и предотвращать уязвимости и неправильную конфигурацию на протяжении всего жизненного цикла приложений, определяя приоритетность рисков ваших облачных сред. Брандмауэры VM-Series помогают обнаруживать вредоносные действия и защищать системы в виртуализированных средах.
Методология исследования
В период с июля по август 2021 года исследователи Unit 42 развернули 320 ханипотов в Северной Америке, Азиатско-Тихоокеанском регионе и Европе. В ходе исследования были проанализированы время, частота и происхождение наблюдаемых в нашей исследовательской инфраструктуре атак.
Четыре типа приложений - SSH, Samba, Postgres и RDP - были равномерно распределены по всей инфраструктуре. Мы намеренно настроили несколько учетных записей со слабыми учетными данными, такими как admin:admin, guest:guest, administrator:password. Эти учетные записи предоставляют ограниченный доступ к приложению в изолированной среде. Ханипот будет сброшен и развернут заново при обнаружении компрометирующего события, т.е. когда атакующий успешно аутентифицируется с помощью одного из наборов учетных данных и получает доступ к приложению.
Для анализа эффективности блокирования сканирующего трафика мы заблокировали список известных IP-адресов сканеров на подмножестве ханипотов. Политики брандмауэра обновлялись раз в день на основе наблюдаемого сканирующего трафика. В зависимости от целевого приложения каждая политика брандмауэра могла блокировать от 600 до 3 000 известных IP-адресов сканеров в день.
Журналы всех точек сбора данных агрегировались на кластере Elasticsearch. Сервер контроллера постоянно отслеживал журналы и проверял состояние каждого ханипота. Если обнаруживалось компрометирующее событие или виртуальная машина переставала реагировать на запросы, контроллер перезаливал виртуальную машину и приложение. На рисунке 1 показана архитектура исследовательской инфраструктуры.
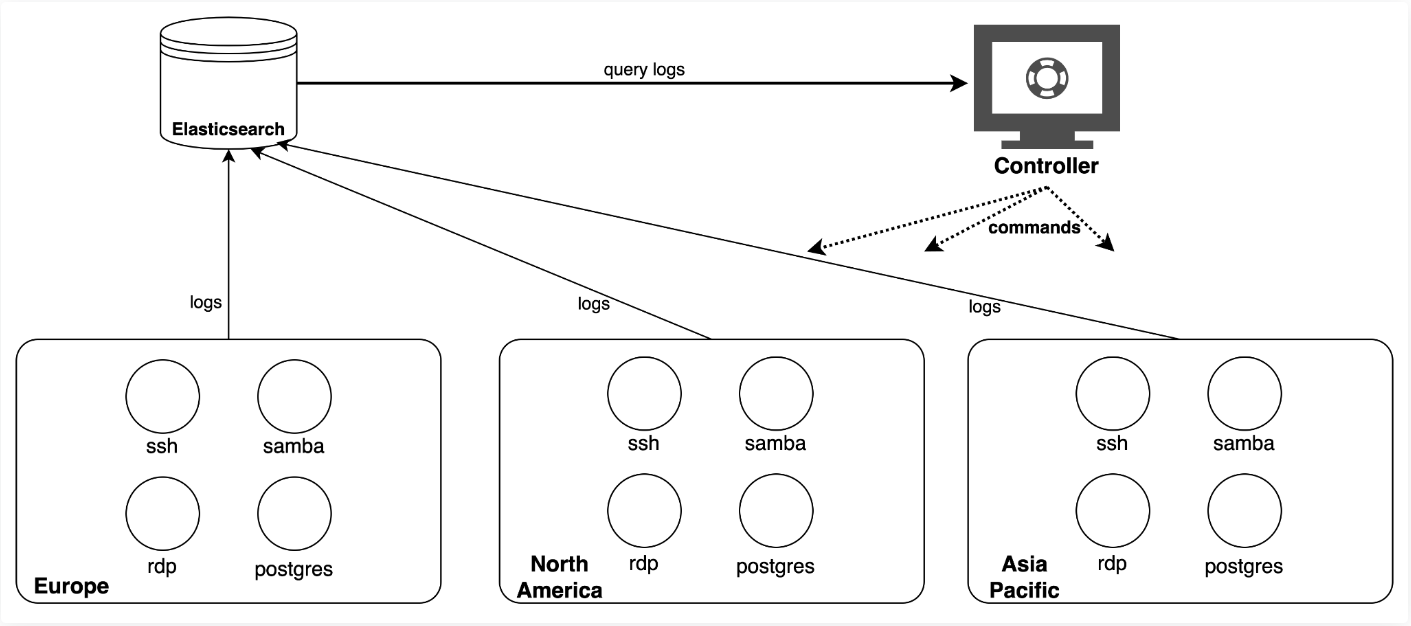
Рис.1.Инфраструктура ханипотов.
Паттерны атак
На рисунках 2-5 анализируется время, частота и происхождение атак. Мы определяем время до первой компрометации как время, в течение которого приложение остается неатакованным с момента запуска. На рисунке 2 показано среднее время до первой компрометации для всех 320 ханипотов. Время до первой компрометации - это время, которое требуется злоумышленникам для обнаружения и компрометации нового сервиса в Интернете. Оно также отражает время, которое требуется ИТ-администраторам, чтобы отреагировать на предупреждение безопасности о незащищенном сервисе, прежде чем они подвергнутся атаке.
Время до первой компрометации варьируется в зависимости от приложения. В целом, оно обратно пропорционально количеству злоумышленников, нацеленных на приложение (Рисунок 4). Когда число атакующих увеличивается, время до первого взлома приложения уменьшается.
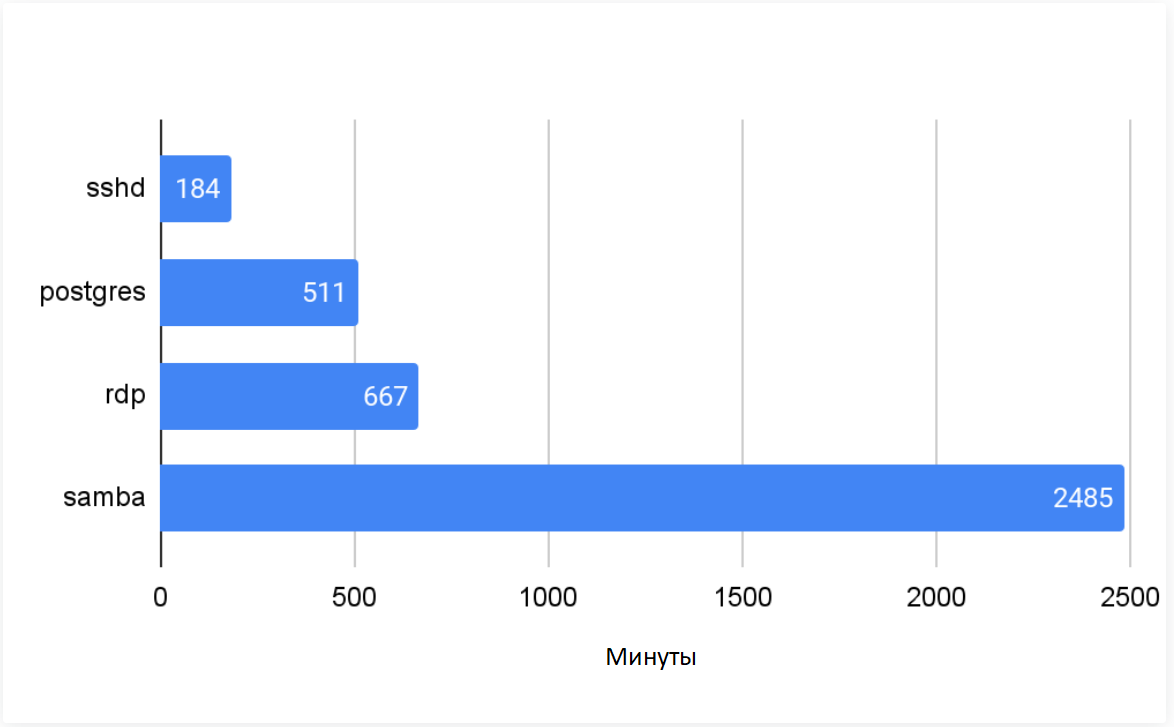
Рис.2.Время между развертыванием ханипота и первым компрометирующим событием.
Среднее время между компрометациями - это среднее время между двумя последовательными событиями компрометации целевого приложения. На рисунке 3 показано среднее время между компрометациями каждого приложения ханипотов в течение 30 дней.
Уязвимый сервис в Интернете обычно взламывается несколько раз разными атакующими. Чтобы конкурировать за ресурсы жертвы, хакеры пытаются удалить вредоносное ПО или бэкдоры, оставленные другими группами (например, Rocke, TeamTNT). Среднее время между компрометациями - это время пребывания злоумышленника на взломанной системе до появления следующего хакера. Как и время до первой компрометации, среднее время между компрометациями приложения обратно пропорционально количеству злоумышленников, атакующих приложение.
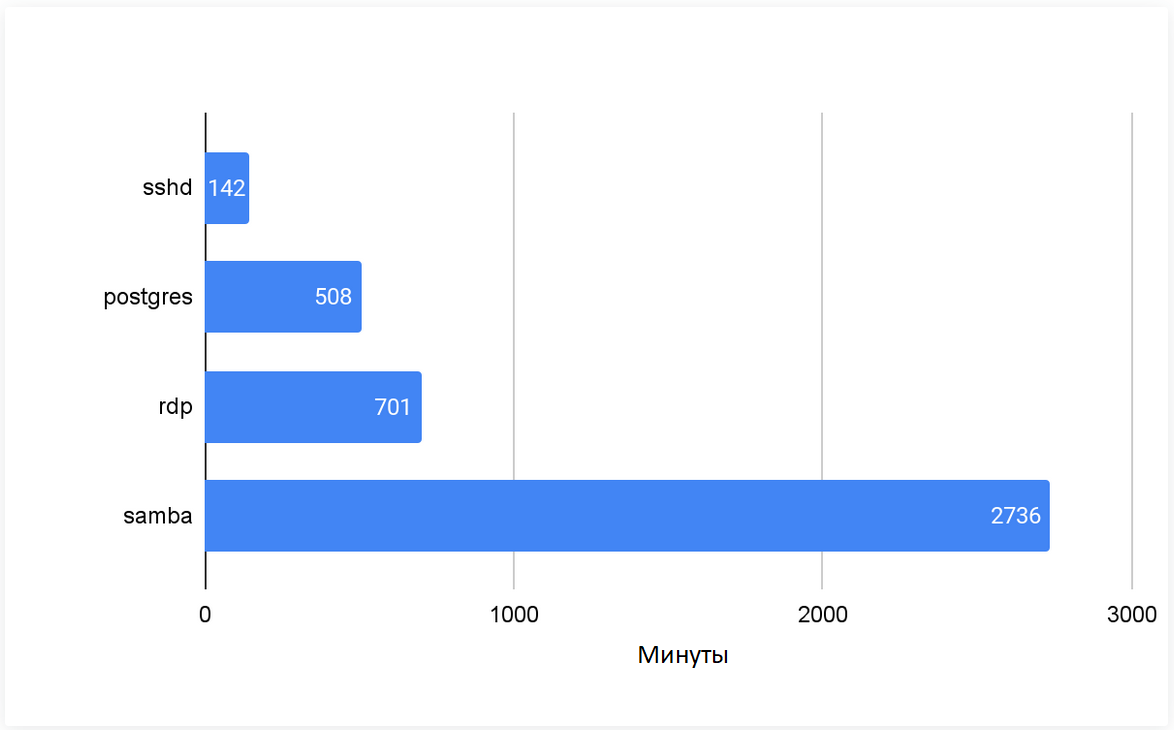
Рис.3.Среднее время между двумя последовательными событиями компрометации приложения.
На рисунке 4 показано среднее количество уникальных атакующитх IP-адресов, наблюдаемых на каждом ханипоте в течение 30 дней. Число также указывает количество раз, когда каждый сервис был скомпрометирован. Обратите внимание - это не количество IP-адресов злоумышленников, наблюдаемых в глобальном масштабе. Поскольку большинство адресов достигают лишь небольшого подмножества наших ловушек, количество глобально наблюдаемых IP-адресов атакующих гораздо выше. В нашем эксперименте только 18% атакующих IP достигли более чем одного ханипота.
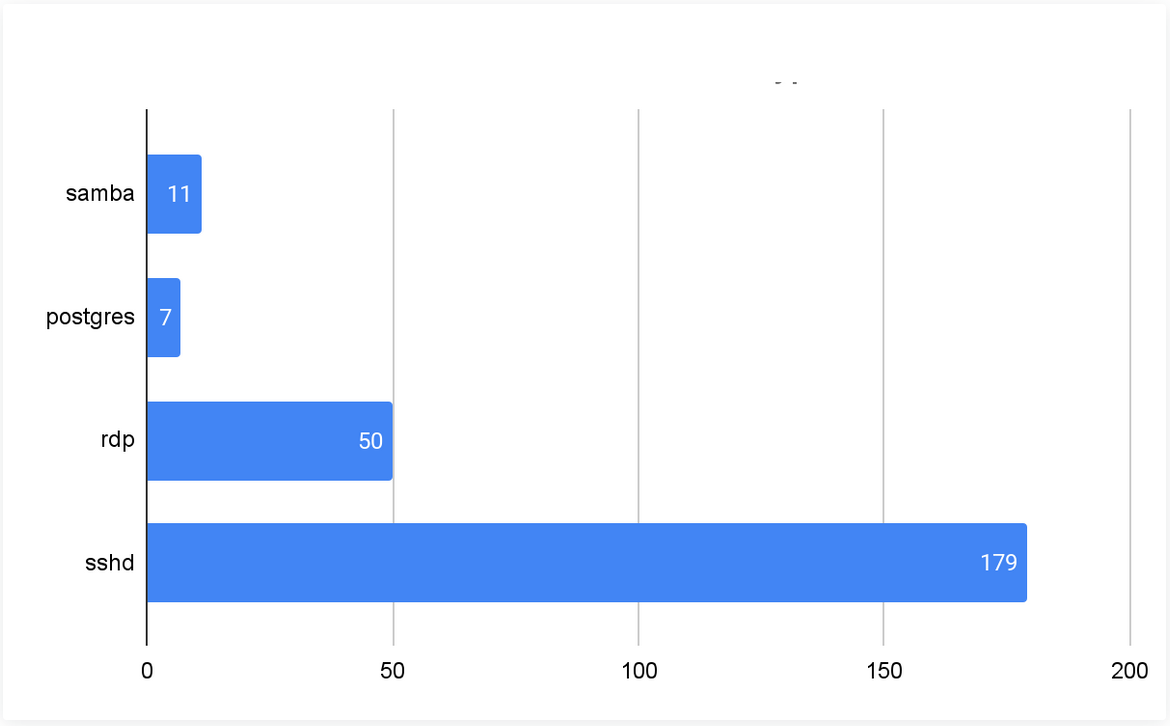
Рис.4.Среднее количество уникальных IP-адресов атакующих за 30 дней.
На рисунке 5 показан процент IP-адресов злоумышленников, неоднократно наблюдавшихся в разные дни. В течение 30 дней, рассматриваемых в данном исследовании, 85% атакующих IP-адресов были замечены только в один день. Это число указывает на неэффективность межсетевого экрана на основе IP-адресов третьего уровня, поскольку хакеры редко используют одни и те же IP-адреса для проведения атак - сегодняшний список вредоносных IP-адресов завтра уже большей частью устареет.
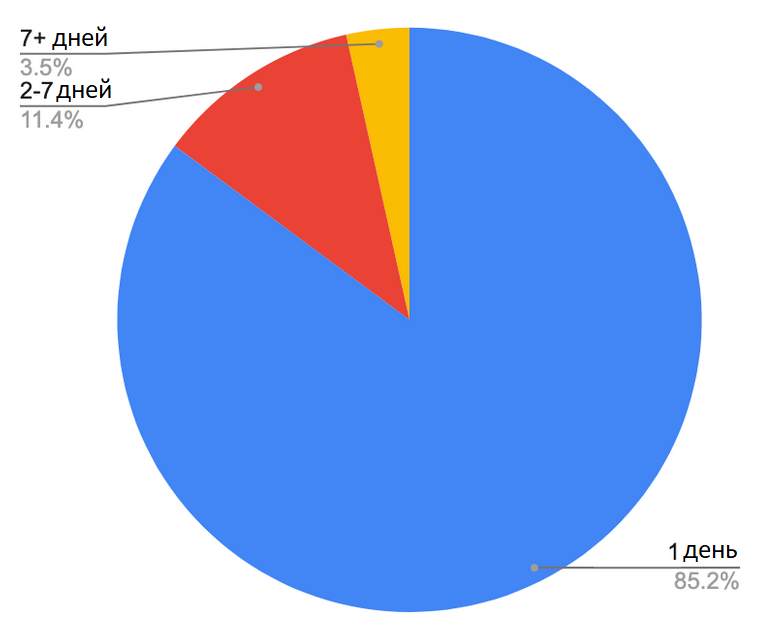
Рис.5.IP-адреса атакующих, замеченные однократно или в течение нескольких дней.
Эффективность брандмауэров
В рамках проекта мониторинга сетевого сканирования ежедневно выявляется более 700 000 IP-адресов сканеров. Нам было интересно, сможет ли проактивная блокировка трафика сетевого сканирования предотвратить обнаружение злоумышленниками наших исследовательских сервисов и снизить количество атак. Чтобы проверить гипотезу, мы создали экспериментальную группу из 48 ханипотов и применили политики брандмауэра для блокирования IP-адресов известных сетевых сканеров. Политика брандмауэра блокирует IP-адреса, которые ежедневно сканировали определенное приложение в течение последних 30 дней. На рисунке 6 сравнивается количество атак, наблюдаемых на каждом сервисе, между контрольной группой (без брандмауэра) и экспериментальной группой (с брандмауэром). Мы не увидели существенной разницы между двумя группами, что означает, что блокирование известных IP-адресов сканеров неэффективно для снижения атак.
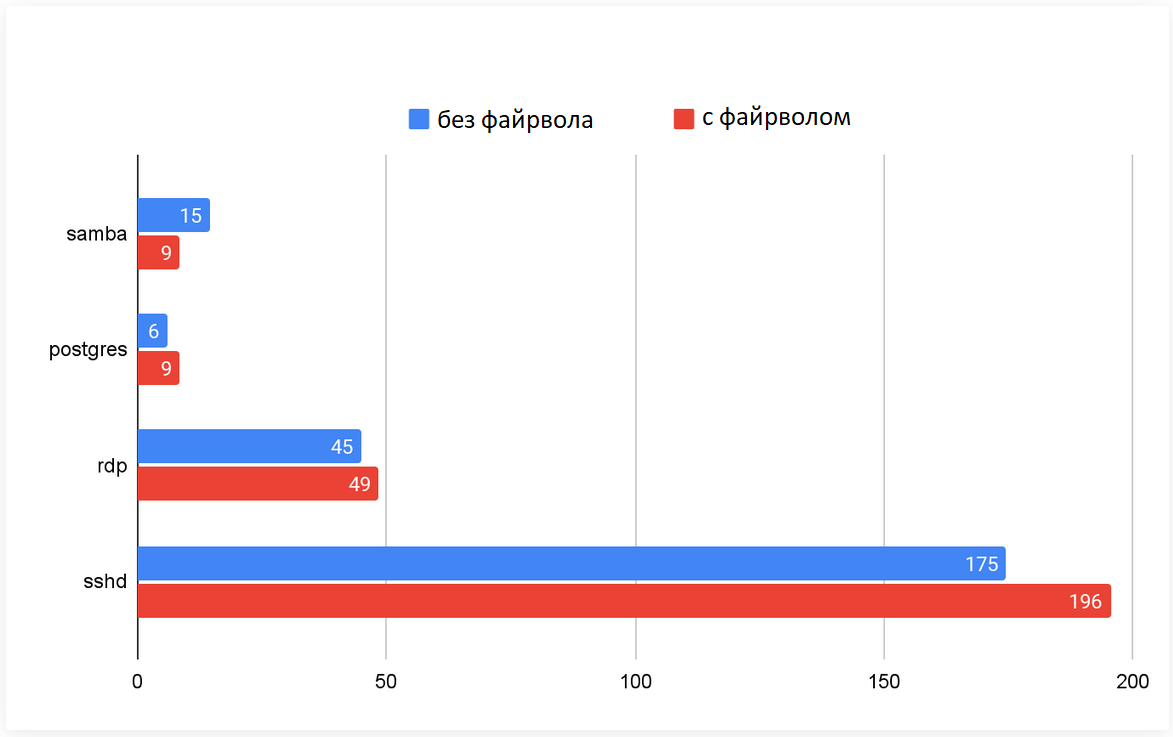
Рис.6.Среднее количество уникальных IP-адресов атакующих с файрволом и без.
Региональное распределение
Нам также интересно, подвергаются ли сервисы в разных географических локациях разным атакам. На рисунке 7 сравнивается количество атак, наблюдаемых на каждом ханипоте в разных регионах. Нет существенной разницы для точек Samba, Postgres и RDP, развернутых в разных регионах, но мы видим очень разную интенсивность атак на SSH-точки. Количество SSH-атак на ханипоты, расположенные в Азиатско-Тихоокеанском регионе, на 50% выше, чем в Северной Америке, и на 263% выше, чем на сервисы в Европе. Эти показатели также интересно коррелируют с происхождением атак, как показано на рисунке 8. 50% IP-адресов злоумышленников поступают из Азиатско-Тихоокеанского региона, 20% - из Северной Америки и менее 10% - из Европы. Результат показывает, что сервисы SSH, развернутые в Азии, чаще подвергаются атакам, чем сервисы в других регионах.
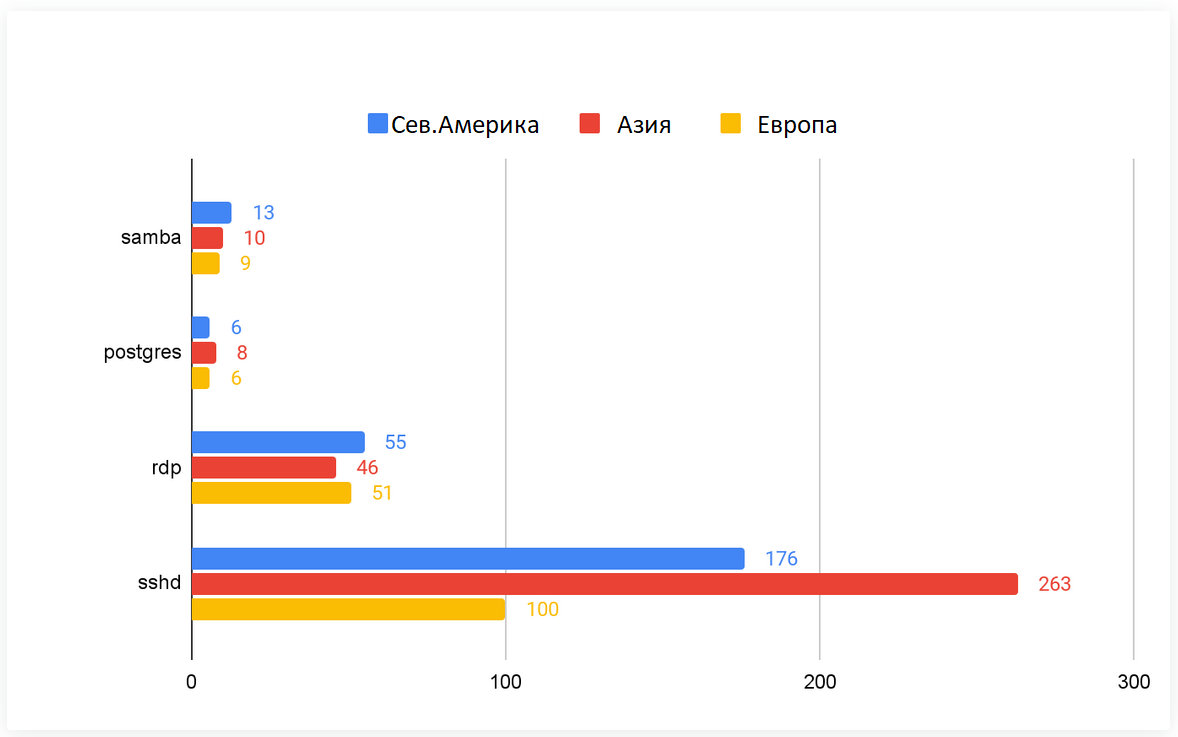
Рис.7. Среднее количество уникальных IP-адресов атакующих в разных регионах.
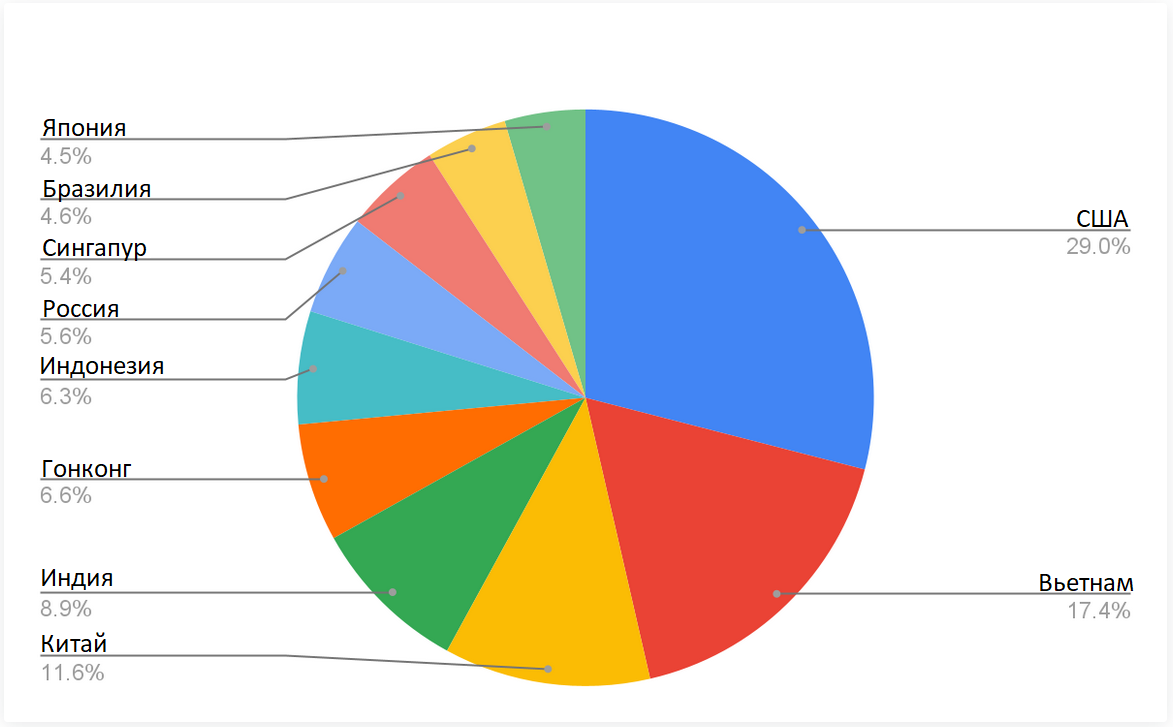
Рис.8.Топ-10 стран происхождения IP-адресов атакующих.
Заключение
Проблема небезопасных открытых сервисов не нова для публичных облаков, но гибкость управления облачной инфраструктурой ускоряет создание и тиражирование таких неправильных конфигураций. Наше исследование подчеркивает рискованность таких неправильных конфигураций. Когда уязвимый сервис открыт для доступа в Интернет, злоумышленники могут найти и атаковать его всего за несколько минут. Поскольку большинство таких выходящих в Интернет сервисов связаны с некоторыми другими облачными рабочими средами, таким образом - любой взломанный сервис может привести к компрометации всей облачной среды.
Неправильную конфигурацию сервиса несложно предотвратить и устранить. Вот некоторые стратегии, которые могут применить системные администраторы:
- Закройте известные привилегированные порты. Например, с использованием политик контроля служб AWS Service Control Policies или Azure Firewall Management..
- Создайте правила аудита для отслеживания всех открытых портов и сервисов. Например с помощью AWS Config, Checkov, или Cloud Security Posture Management .
- Создавайте правила автоматического реагирования и исправления для автоматического устранения неправильных конфигураций. Например, используйте AWS Security Hub или Prisma Cloud Automated Remediation.
- Разверните межсетевой экран нового поколения перед приложениями - например, VM-Series или WAF - для блокирования вредоносного трафика.
Источник: https://unit42.paloaltonetworks.com
