
Новый метод атаки нацелен на вывод нажатий клавиш, набранных целевым пользователем на противоположном конце видеоконференции путем простого использования видеосигнала и соотношения наблюдаемых движений тела с набираемым текстом.
Исследования были проведены Мохд Сабра и Муртузой Джадливала из Техасского университета в Сан-Антонио и Аниндой Майти из Университета Оклахомы, которые утверждают, что атака может быть расширена за пределы «живых» видео-звонков до тех, которые транслируются на YouTube и Twitch или вообще любых видео, на которых веб-камера в поле зрения захватывает видимые движения верхней части тела пользователя-жертвы.
«С недавним повсеместным распространением оборудования для захвата видео, встроенного во многие устройства бытовой электроники, такие как смартфоны, планшеты и ноутбуки, угроза утечки информации по визуальным каналам усилилась» - сообщают исследователи. «Цель атакующего состоит в том, чтобы использовать наблюдаемые движения верхней части тела по всем записанным кадрам, чтобы сделать вывод о приватном тексте, набранном жертвой».
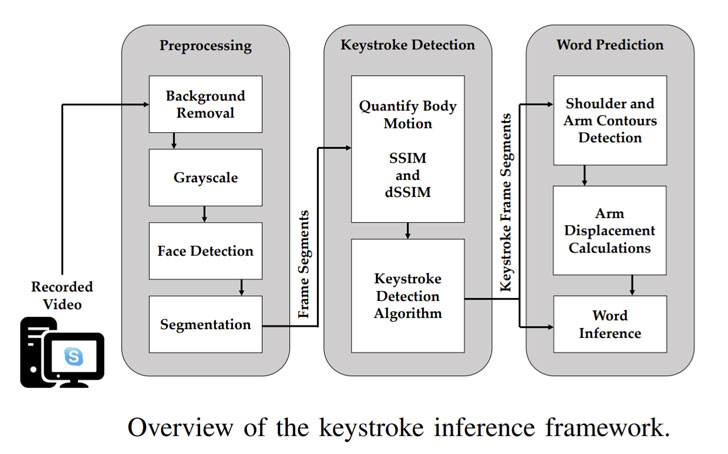
Для осуществления атаки записанное видео подается в основанный на нажатии клавиши фреймворк обработки видео. Фреймворк производит обработку в три этапа:
- Предварительная обработка, при которой удаляется фон, видео преобразуется в градации серого, после чего сегментируются области левой и правой руки относительно лица человека, обнаруженного с помощью модели FaceBoxes.
- Обнаружение нажатия клавиш, при котором извлекаются сегментированные кадры руки для вычисления индекса структурного сходства (SSIM) с целью количественного определения движений тела между последовательными кадрами в каждом из сегментов видео и определения потенциальных кадров, в которых произошли нажатия клавиш.
- Прогнозирование слов, где сегменты рамок нажатия клавиш используются для обнаружения признаков движения до и после каждого обнаруженного нажатия, используя их для вывода определенных слов с помощью алгоритма прогнозирования на основе словаря.
Иными словами, слова из пула обнаруженных нажатий клавиш выводятся по количеству обнаруженных для слова нажатий, а также по величине и направлению смещения плеча, которое происходит между последовательными нажатиями клавиш слова.
Это смещение измеряется с помощью техники под названием «Sparse optical flow», которая используется для отслеживания перемещений плеча и руки через хронологические рамки нажатия клавиш.
Кроме того, шаблон для «направлений между нажатиями клавиш на стандартной QWERTY-клавиатуре» также нанесен на карту, чтобы обозначить «идеальные направления, которым должна следовать рука печатающего» при использовании при печати обеих рук.
Затем алгоритм прогнозирования слов ищет наиболее вероятные слова, которые соответствуют порядку и количеству нажатий левой и правой рукой, а также направлению смещения рук с помощью шаблона направлений между нажатиями.
По словам исследователей, они протестировали фреймворк с 20 участниками (9 женщин и 11 мужчин) в контролируемом сценарии, используя сочетание «зрячего» и «слепого» методов печати, оттестировали алгоритм вывода на различных фонах, моделях веб-камер, одежде (в частности, дизайне рукавов), клавиатурах и даже различных программах для видеосвязи, таких как Zoom, Hangouts и Skype.
Полученные результаты показали, что печатающие «зряче» и люди без рукавов, а также пользователи веб-камер Logitech были более восприимчивы к атаке, что привело к лучшему восстановлению слов. Хуже удавалось атаковать тех, кто пользовался внешними веб-камерами Anivia.
.jpg)
Тесты были повторены с 10 участниками (3 женщины и 7 мужчин), на этот раз в «домашних» условиях видеоконференции, с успешным выводом 91,1% имен пользователей, 95,6% адресов электронной почты и 66,7% сайтов, набранных участниками, 18,9% паролей и 21,1% набранных случайных английских слов.
«Одна из причин, по которой точность в «домашнем» эксперименте хуже, чем в лабораторных условиях, заключается в том, что сортировка рангов в справочном словаре основана на частоте употребления слов в предложениях английского языка, а не на случайных словах, произносимых людьми» - отмечают Сабра, Майти и Джадливала.
Отметив, что размытие, пикселизация изображения и пропуск кадров могут быть эффективным методом противодействия подобной атаке, исследователи сказали, что видеоданные могут быть объединены со звуковыми данными из звонка для дальнейшего улучшения обнаружения нажатия клавиш.
«В связи с недавними событиями в мире, видеозвонки стали новой нормой, как для личного, так и для профессионального удаленного общения», подчеркивают исследователи. «Однако если участник видеозвонка не проявляет осторожность, он может раскрыть свою личную информацию другим участникам звонка. Относительно высокая точность эксперимента при часто встречающихся и реалистичных настройках видеоконференции подчеркивает необходимость осознания и противодействия таким атакам».
Ожидается, что результаты будут представлены на Симпозиуме по сетевой и распределенной системной безопасности (NDSS).
Перевод сделан со статьи: https://thehackernews.com
